Text to Speech vs. Speech to Text

Have you ever used a voice search assistant for a query on your browser or a phone? If yes, then there's no better instance of speech to text in action in your daily life. Along the same lines, if you've used the "pronunciation" tool on Google to learn how a word is spoken, you now understand what text to speech is.
Text to speech (TTS) and Speech to text (STT) are two entirely different technologies, although they do work on the same concept—the use of graphemes, phonemes, and Mel-spectrograms—for converting one form of language into another. TTS has been received quite well all over the world over and is set to reach a market capital value of $6.52 billion by 2027.
Similarly, speech to text is also prominently noticeable today in the form of dictation tools on software like MS Word. In fact, the market for speech to text is growing at a CAGR of over 15% (2022 to 2030).
There's so much more to these tools than their market performance. There is a detailed process that happens behind the scenes within seconds that produces the output. Here is a deeper insight into text to speech vs speech to text.
Table of Contents
What is Text to Speech?
Text to speech is a noble technology that reads text aloud. You may also know this tool as "Read Aloud" on products like eBooks and e-readers. It is an assistive technology that enables those with visual impairments and learning disabilities to consume information on digital channels such as emails, blogs, social media, and websites and understand text better by listening to it.
Text to speech also enables businesses to drastically expand their audience outreach to previously inaccessible demographics. It promotes inclusivity for your brand.

What is Speech to Text?
Speech to text is a computational linguistics technology that uses speech recognition or an audio file to convert spoken language into text. Its best example is the Dictate tool in Microsoft Word, which allows users to dictate or spell a word out loud instead of typing it in their documents. Dictate's AI engine and machine learning algorithms process the spoken word and convert it into accurate text.
You can even translate your speech using the right tool with translation capabilities. The language you speak can easily be converted into text in a different language using speech to text.
That said, STT is a revolutionary tool for improving productivity. It also helps physically-challenged people use the internet or create documents and fill out forms on a digital platform without having to type it.
Difference between Text to Speech and Speech to Text
While seemingly similar, text to speech and speech to text have certain technological and applicational differences that make them unique and extremely useful in their own niches.
Differences in Processing and Output
Text to speech and speech to text are processed differently.
For text inputs, pre-processing converts the text into phonemes with the linguistic features and properties of the target language.
At this stage, the AI engine normalizes the text input (like converting 'Nov' to 'November') before it converts the grapheme input into corresponding phonemes.
The converted vector forms are fed into the acoustic model, which then transforms these into Mel-spectrograms to make the audio output sound as close to lifelike as possible.
The last step of text to speech involves feeding the Mel-spectrograms into a neural vocoder. This function converts the spectrograms into waveforms or audio.
For speech-based inputs, an element of automatic speech recognition (ASR) is involved.
The pre-processing of input speech waveforms involves modifying the speech signal such that its linguistic features can be extracted from the accompanying background noise.
Normalization of speech as input is then achieved by eliminating the energy pertaining to the unwanted sound to isolate voiced speech and process it further.
The AI engines break down the normalized input into thousands of segments and match each one to the corresponding phoneme. The corresponding grapheme is then presented on the screen as text.
Differences in Input Prompts
As is evident, there is a clear difference in the type of input that text to speech and speech to text work with.
Text to speech uses text as input—whether already on the screen or upon typing by a user. STT uses voiced sounds as input for its speech recognition module.
Differences in Output
The output for TTS is an AI voice that closely resembles human speech. The closeness to human speech depends on how well the TTS tool is trained and equipped.
The output for STT is readable text on the screen in the preferred language.
Differences in Application
TTS is used across the internet to improve website and digital channel accessibility. It is also used for read-aloud applications in eBooks, e-readers, video voiceovers across industries, special/assisted learning tools, comprehension improvement tools and other assistive applications.
STT is used extensively in transcription technologies where voiced speech needs to be translated. It also finds use in dictation tools, media subtitling, documentation in clinical studies/treatments, voice commands on consumer devices, and more.
Text to speech and speech to text technologies are still evolving into better forms and performance. The future will see expanded uses and applications for these technologies.
How do Text to Speech and Speech to Text Work?
The working of text to speech and STT is fairly simple to understand.
TTS Technology: How it Works
The conversion of text to speech is a four-step process. It begins with pre-processing:
The text you input is input into the pre-processor, which breaks it up into phonemes. Each phoneme has its own specific duration in the audio.
The phonemes, which are the latent features of the input, are then sent to the encoder, which embeds them with the “Speaker” before sending them to the decoder.
The decoder then processes these latent features and determines the energy, duration, and pitch to convert them into Mel-spectrograms.
Mel-spectrograms, also called acoustic features, are then sent into vocoders to convert into speech waveforms.
Broadly speaking, there are two components of converting text to audio:
Transforming input text into Mel-spectrograms
Converting Mel-spectrograms into audio
STT Technology: How it Works
The conversion of speech to text online relies on ASR technology. Here's how it works:
When you “speak,” the sound waves you produce are analog signals of sound. In order to be computed by software for conversion, these analog signals are first digitized. This digitization happens by breaking down the acoustics into segments.
Each acoustic segment is then analyzed by the ASR software. It matches each segment to its corresponding phoneme—elements of human speech used to create meaningful expressions.
Once all the phonemes are matched, the software then locates the respective grapheme for each phoneme. Graphemes are words, phrases, or symbols that correspond to linguistic phonetics.
The software then analyzes the context of the speech to establish relationships between the spoken words. It helps eliminate errors between words like “piece” and “peace.”
The output is speech to text!
Text to Speech with Murf
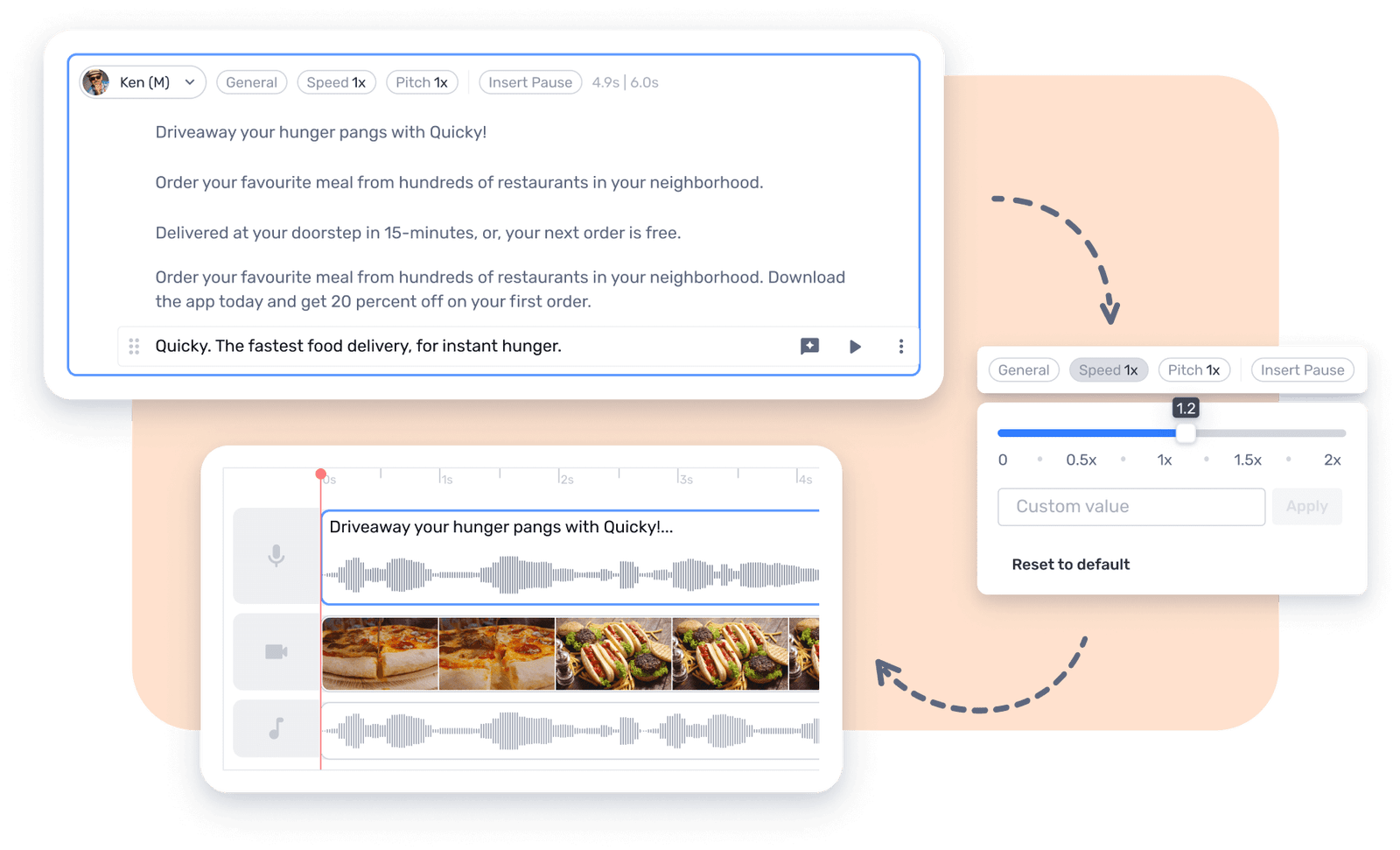
Text to speech is so much more than just a technology—today, it is a necessity. With Murf, your business is empowered to take text to speech beyond robotic enunciation—we provide realistic AI voices.
A selection of the most humanlike AI voices spanning over 20 languages lets you humanize your brand…without humans.
Murf has a voice for every use case. Whether you're a business in the corporate, entertainment, or creative niches, we have AI voices that match the industry characteristics to the T.
Experience Murf's power of branding through our comprehensive text to speech platform that lets your business customize the pitch, pause instances, pronunciations and vernacularization, word emphasis, and narration nuances for the AI voices you choose.
With Murf's AI voices, your business can create a tangible difference in the form of cost savings, time savings (in editing the audio), and achieving brand consistency. Our polyglot tool helps your business' online channels go global with minimal investment and maximum ROI.
Empower your business with intelligent savings and content delivery tied together with industry-leading AI voices. Leverage the power of humanization, inclusivity, and accessibility without the high costs all with Murf AI's text to speech service.

FAQs
How do I use speech to text?
STT is available on most mobile phones and laptops today in the form of voice-based typing applications. However, the transcription capabilities and accuracy of these applications are limited.
If you're looking for a large-scale transcription operation, it's better to select a full-scale speech to text tool with advanced AI capabilities that help you get the job done quicker.
Do text to speech systems provide API integration?
Yes, text to speech systems like Murf AI do allow API integration. Text to speech APIs let your business configure your TTS modules for all the digital channels and provide a unified console for orchestrating these operations. API integrations make it easy for your organization to couple TTS/STT tools with other software or applications in use at your organization. It is key to choose TTS tools that provide this functionality.


